

B تاریخچه به وجود آمدن موتورهای جستجو
از همان دوره پیشاوب (اواخر دهه 1980 میلادی) و زمانی که از شبکه اینترنت – به طور خاص بر پایه سرویس FTP [1] – به عنوان بستر ذخیره و انتقال اطلاعات بین کاربران استفاده میشد، قابلیت جستجو و یافتن اینکه یک محتوا در کدام سرور ذخیره شده است، نیازی اساسی بود. به همین خاطر پیش از به وجود آمدن موتورهای جستجو، این کار به صورت دستی انجام میشد و برخی کاربران به فراخور آنچه حین اینترنتگردی به آن بر میخوردند، لیستی از نشانی اینترنتی پروندههای (فایلهای) موجود روی سرورهای مختلف را ثبت و منتشر میکردند.
این ایده کمی بعدتر به صورت سازماندهی شدهتر در قالب نرمافزار دانشگاهی «Archie» اجرا شد که به کاربر این امکان را میداد بیابد پرونده مورد نظرش روی کدام سرورهای عمومی FTP قرار دارد. از این حیث میتوان «Archie» را اولین جویشگر اینترنت در نظر گرفت.
شکل 61: اولین جویشگر اینترنت به نام Archie که به کمک آن میشد سرور محل ذخیره فایل را در اینترنت پیدا کرد. [2]
اما پس از تولد و عرضه عمومی وب در سال 1370/1991 بر بستر شبکه اینترنت، دیگر کاربرد این شبکه صرفاً انتقال پرونده (فایل) نبود و میشد با استفاده از کدهای HTML [3]، صفحات وب و تارنما (وبسایت) ایجاد کرد و محتوای متنی، تصویری و بعدتر ویدیو و صوت دلخواه را برای دیگران به نمایش گذاشت.
همچنین این امکان به وجود آمد تا به مطالب و مقالات موجود در وب، ارجاعات متنی و پیوند (لینک) از یک نشانی اینترنتی به نشانی دیگر افزوده شود. این باعث شد وب تبدیل به یک کتابخانه بزرگ چندرسانهای شود که به راحتی میتوان میان محتویات آن پیوند زد و از صفحهای به صفحه دیگر ارجاع داد. از این رو استقبال از اینترنت و تولید محتوا بر بستر وب به شدت افزایش یافت.
اما در سوی دیگر چالش جستجو در وب نیز پیچیدهت
ر شد: تا پیش از این صرفاً نام و پسوند پروندههای موجود روی سرورها مورد جستجوی کاربران بود و موتورهای جستجویی مثل «Archie» کاری به محتوا نداشتند، اما حالا باید چه چیزی فهرست میشد: عنوان صفحه؟ فراداده (متادیتا)[4]؟ پیوندها (هایپرلینک)؟ یا متن کامل صفحه؟
برای پاسخ به چنین نیازی بود که تارنماهای ارائهدهنده خدمت «فهرست راهنمای وب»[5] نظیر «Yahoo!» (از سال 1373/۱۹۹۴) شروع به کار کردند. این پایگاههای اینترنتی به صورت دستی و طبق نظر هیئت تحریریه خود، سایر تارنماهای موجود در وب را رصد کرده و آنها را دستهبندی موضوعی و درجهبندی میکردند.
شکل 62: شکلوشمایل نخستین اولین نسخه از پایگاه اینترنتی Yahoo! [6]
اما این راهکار به سرعت با مشکل مواجه شد: اولاً سرعت گسترش وب فراتر از آنی بود که بتوان آن را به صورت دستی فهرستبندی کرد. ثانیاً محتوای روی وب پویایی و پیچیدگی دارد که نمیتوان آن را در دستهبندیهای موضوعی ثابت تقسیمبندی کرد.
برای همین، «موتورهای جستجو»[7] نظیر «Google» (تأسیس 1377/1998) یا «Bing» (تأسیس 1377/1998 به نام MSN) یا «Yandex» (تأسیس 1376/1997) یا «Baidu» (تأسیس 1379/2000) به وجود آمدند.

شکل 63: سیر زمانی آغاز به کار موتورهای جستجوی معروف
B طرز کار جویشگر
تفاوت اصلی جویشگرها با فهرستهای راهنمای اینترنت (نظیر یاهو) این است که به جای فهرستبندی دستی پایگاهها، جویشگرها از رباتهای پایشگری استفاده میکنند که به صورت خودکار صفحات وب را مرور و فهرستبندی میکند. سپس متناسب با «جُستار» (کوئری)[8] کاربران، پاسخهای مناسب را ارائه میکنند. اما چگونه؟
پایهایترین نکتهای که باید درباره شیوه عملکرد موتورهای جستجو دانست این است که آنها بلافاصله بعد از جستجوی کاربر به دنبال نتایج نمیگردند؛ بلکه این کار را از مدتها پیش انجام دادهاند!
در واقع موتورهای جستجو فارغ از جستجوی کاربران، صفحات وب را به طور متناوب و در بازههای زمانی مختلفی رصد و پایش میکنند. بدینصورت که محتوای برخی تارنماهای از پیش شناخته شده اولیه را پیمایش میکنند و به محض برخوردن با هر پیوند، به تارنمای جدید مراجعه کرده و محتوای آن را نیز پایش و ذخیره میکنند و اگر در آنجا نیز پیوند جدیدی بود، به تارنمای بعدی مراجعه میکنند و الی آخر… لذا به جهت شباهت این رفتار با نحوه حرکت عنکبوت روی تار، به این عمل «خزش» (Crawl) و به رباتهایی که این کار را به صورت خودکار انجام میدهند «عنکبوت» (Spider) میگویند؛ ربات موتور جستجو روی شبکه تور مانند وب، از گرهی (تارنما) به گره دیگر حرکت میکند.[9]
پس از خزش، محتوای تارنماها (اعم از متنها، تصاویر، ویدیوها، پروندهها و …) ذخیره و «فهرستبندی» (Indexing) میشود. اما موضوع بعدی این است که از میان انبوه محتوای فهرست شده، کدام نتایج و با چه ترتیبی به مخاطب نمایش داده شود؟ اینجاست که اهمیت سازوکار رتبهبندی هر موتور جستجو مشخص میشود.
به طور کلی، هر موتور جستجو الگوریتم اختصاصی خود را بهمنظور رتبهبندی و شخصیسازی نتایج برای کاربران دارد؛ مثلاً در مورد گوگل از تلفیق بیش از ۲۰۰ شاخص مختلف حاصل میشود. البته جزئیات دقیق این شاخصها محرمانه هستند اما برخی از آنها طی سالها و به صورت تجربی نزد کاربران مشخص شدهاند.[10] برای مثال:
- شاخص «کیفیت صفحه»: شامل اینکه محتوای صفحه کپی نباشد و تعداد کلمات آن قابل توجه باشد، تصاویر مرتبط و اختصاصی در آن استفاده شده باشد، پیوند به سایر تارنماها داشته باشد و نهایتاً به قدری کامل باشد که کاربران نیز مدت زمان طولانی در صفحه باقی بمانند.
- شاخص «موقعیت»: بسته به مکان جغرافیایی که کاربر جستجو را انجام میدهد نتایجی که از حیث موقعیت نزدیکتر به وی هستند با اولویت بالاتر نمایش داده میشوند.
- شاخص «زبان»: نتایج همزبان با عبارت جستجو شده توسط کاربر در اولویت بالاتر قرار میگیرند.
- شاخص «جستجوهای قبلی کاربر»: نتایج نمایش داده شده با توجه به سوابق جستجوهای کاربر اختصاصیسازی میشود.
با توجه به اهمیت رتبه تارنمای کسبوکارها در نتایج موتورهای جستجو بهمنظور گرفتن بازدید ورودی، امروزه صنعت «سئو»[11] یا «بهینهسازی برای موتورهای جستجو» نیز بر پایه شناسایی همین شاخصها و دادن مشاوره به مدیران تارنماها رونق ویژهای یافته است. هرچند موتورهای جستجو نیز به منظور پیشگیری شناسایی و جلوگیری از نمایش تارنماهای متقلب، مدام الگوریتمهای خود را تغییر میدهند.
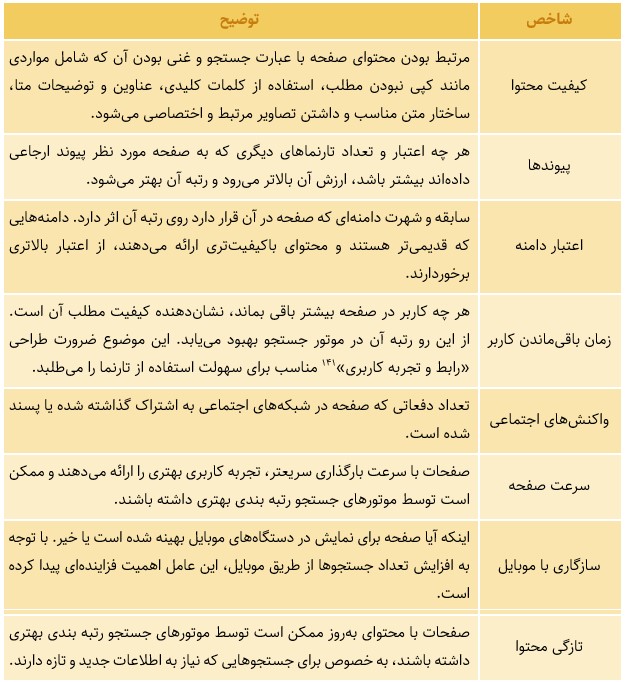
جدول 5: برخی از شاخصهای «سئو» و بهبود رتبه تارنما در موتورهای جستجو
B الگوی درآمدی جویشگرها
سؤال مهمی که ایجاد میشود این است که موتورهای جستجو با این گستره فعالیت و نیازهای سنگین زیرساخت فنی برای خزش، پایش، فهرستبندی و رتبهبندی محتواها، چطور رایگان هستند؟!
خلاصهترین پاسخ این است: موتورهای جستجویی مثل گوگل ابتدا توانستند بر پایه کلمات کلیدی صفحات وب را به جستجوی کاربران مرتبط کنند؛ و از این طریق محبوب شدند. در گام بعد توانستند برای این کلمات کلیدی ارزش تجاری ایجاد کنند؛ و از این راه پولدار شدند![12]
در واقع اگرچه از ابتدای شکلگیری سرویسهای جستجوگر وب – اعم از فهرستهای راهنمای وب و بعداً موتورهای جستجو – نمایش تبلیغات در گوشه و کنار صفحات تارنما از راههای درآمدزاییشان بوده و هست، اما قابلیت ویژهای که موتورهای جستجو دارند عبارت است از کلاندادهای که از انبوه عبارات جستجو شده توسط کاربران در زمانها و مکانهای مختلف شکل دادهاند.
ارزشمندی این کلانداده از این جهت است که میتواند مشخص کند چه کاربرانی (از حیث سن، جنسیت، طبقه اجتماعی، گونه شخصیتی و …) چه زمانی (صبح، ظهر، شب، بعد مدرسه، در ساعت اداری و …) و در چه مکانی (داخل خانه، سر کلاس مدرسه، در محل اداره و …) چه چیزی را جستجو میکنند. به عبارت دقیقتر این شرکتها بر پایه دادهای که از کاربران دارند میتوانند بگویند افراد در هر زمان به چه موضوعی فکر میکنند یا چه کالایی را نیاز دارند یا به چه کسی میخواهند رأی بدهند یا … .
چنین دادهای مسلماً برای شرکتهای تبلیغاتی، کمپینهای فرهنگی، احزاب سیاسی، نهادهای امنیتی و غیره جذابیت دارد و حاضرند برای آن پول خرج کنند. بهطوریکه مثلاً در سال 1402/2023 نزدیک به 80 درصد درآمد شرکت گوگل، معادل 200 میلیارد دلار، از طریق سرویسهای مرتبط با جستجو و تبلیغات آن بوده است.[13]
البته باید دانست که پشت این مدل درآمدی پر سود برای موتورهای جستجو، کاربران نیز بهای سنگینی میپردازند… چراکه این مدل بر این اصل استوار است که کاربران پذیرفتهاند در قبال دریافت خدمات اینترنتی رایگان از سکو (پلتفرم)، آن سکو اجازه داشته باشد اطلاعات/هویت/توجهشان را به عنوان محصول به شرکتهای دیگر بفروشد، تا … !
در واقع «موتورهای جستجو» از یک سمت نتایج جستجو را برای «کاربران» فراهم میکنند، و از سمت دیگر «کاربران» را برای «ارائهکنندگان محتوای تجاری/فرهنگی/سیاسی/امنیتی»…
B چالشهای جویشگرها
نگرانیها پیرامون موتورهای جستجو فراتر از حریم خصوصی و فروش اطلاعات هویتی کاربران است. تهدید بزرگتر، دستکاری غیرمستقیمی است که موتورهای جستجو در ادراک کاربران نسبت به جهان واقعی ایجاد میکنند.
در واقع موتورهای جستجو در رقابت برای اینکه کاربران بیشتری جذب و آنها را راغب به استفاده از سکوی خود کنند، تلاش دارند الگوریتم جستجوگر را طوری طراحی کنند که بتواند بهتر منظور کاربر را از پرسش بفهمد و مرتبطترین نتایج را برای جستجوی هر کاربر ارائه کند. از این رو به سمت شخصیسازی نتایج رفتهاند.
مثلاً گوگل از سال ۱۳۸۸/2009 برای همه کاربران (حتی اگر وارد حساب جیمیل خود نشده باشند) بر اساس شناسه IP یک «نشست»[14] باز میکند و تمامی جستجوها و صفحاتی که کاربر مشاهده کرده را ثبت میکند. سپس با اتکا به این سابقه و سایر دادههایی که از قبل درباره کاربر دارد، پاسخها و پیشنهادات اختصاصی به وی ارائه میکند.
این سوگیری موتورهای جستجو سبب میشود کاربران به مرور در «حباب فیلتر»[15] (یا حباب اطلاعاتی) به دام افتند: یعنی به جای دریافت اطلاعات صحیحتر یا متفاوت از دیدگاه فعلیشان که به آنها وسعت نگاه میدهد، دائماً با همان چیزی مواجه میشوند که قبلاً میدانستند و تأییدکننده عقاید و نظرات پیشینشان است. اما برای گریز از این حباب فیلتر و شکستن انحصار اطلاعاتی گوگل چه میتوان کرد؟

شکل 64: موتورهای جستجو با جمعآوری اطلاعات شخصی کاربران و ارائه محتوا اختصاصی شده به آنها، عملاً یک «حباب اطلاعاتی» دور افراد تشکیل میدهند.
B جایگزینهای گوگل
واقعیت این است که گوگل به واسطه زنجیره خدمات کاملی که دارد (موتور جستجو، سرویس رایانامه «جیمیل»، مسیریاب «مپس»، سرویس اشتراک ویدیو «یوتیوب»، سیستم عامل موبایل «اندروید»، مرورگر «کروم» و …) بدون شک قدرت منحصر به فرد این حوزه است و به گواه آمار سال 1402/2023 بیش از 90 درصد بازار موتورهای جستجو در دنیا را در اختیار دارد. حتی رقیب بعدی آن، جستجوگر «بینگ» شرکت مایکروسافت، با فاصله زیاد فقط 3 درصد سهم دارد.
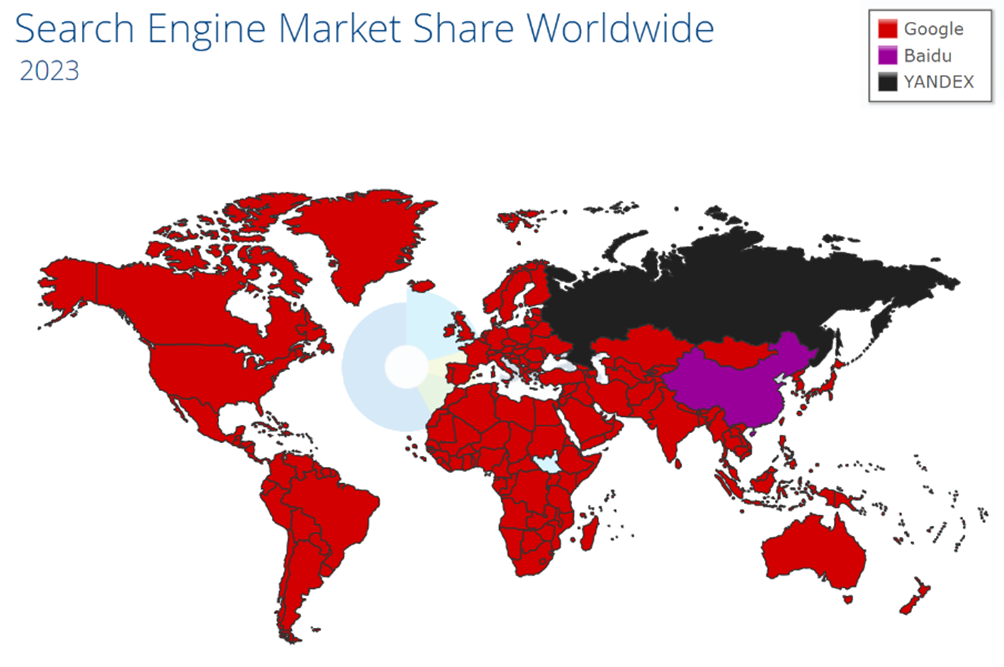
شکل 65: نقشه سهم بازار موتورهای جستجو در جهان در سال 2023 (پیشتازی گوگل بجز چین و روسیه)[16]
با این وجود تجربههای جهانی نشان میدهد که هنوز میتوان در زمینههایی از جایگزینهای مناسبتر و حتی باکیفیتتر از گوگل استفاده کرد. برای مثال:
- موتور جستجوی «بایدو»[17] (از 1376/1997) در چین و «یاندکس»[18] (از 1379/2000) در روسیه توانستهاند با تکیه بر مزیت رقابتی ارائه خدمات بومی (مثلاً ترجمه با کیفیت زبانها به روسی و چینی، سرویس تاکسی اینترنتی، سفارش غذا، نقشه مسیریاب، کتابخانه مجازی و …)، به ترتیب 67 و 64 درصد از سهم بازار موتورهای جستجو در کشورهای خودشان را از آن خود کنند و انحصار گوگل را به چالش بکشند. همچنین موتور جستجوی ملی کره جنوبی به نام «ناور»[19] (از 1378/1999) نیز رقابت تنگاتنگی با گوگل در این کشور دارد.
- موتور جستجو و مرورگر «داکداکگو»[20] (از 1387/2008) نیز به واسطه ضوابط حریم خصوصی خود بسیار مورد اقبال کاربران قرار گرفته است. این جویشگر ادعا میکند هیچ اطلاعات جانبی از کاربران جمعآوری و ذخیره نمیکند و منبع درآمد آن از طریق دریافت سفارش تبلیغات بر اساس نتایج (نه سوابق کاربران) است.[21]
- جویشگر هلندی «StartPage»[22] (از 1381/2002) نیز یک ابزار جستجوی واسط برای حفظ حریم خصوصی است. این موتور جستجو همان نتایج گوگل را نمایش میدهد اما آیپی کاربر را مخفی نگه میدارد.
- «Dogpile» به عنوان یک «موتور جستجوی فراداده»[23] است که نتایج گوگل، بینگ، یاهو و یاندکس را یکجا تجمیع کرده و نمایش میدهد و از این حیث میتواند برای گریز از حباب اطلاعاتی مفید باشد.
- نرمافزار رایگان «YaCy»[24] که یک موتور جستجوی غیرمتمرکز نقطه به نقطه است و به کاربر این قابلیت را میدهد که خود تعیین کند چه تارنماهایی و تا چه عمقی خزش و بر اساس چه شاخصهای فهرستبندی شوند. از این طریق میتوان موتور جستجوی اختصاصی خود را ساخت.
در ایران نیز راهاندازی و توسعه موتورهای جستجوی ملی از سال 1389 با جستجوگر «پارسیجو» آغاز شد و پس از آن با تجربههایی نظیر «یوز»، «سلام» و «گردو» دنبال شد. با اینحال در حال حاضر جستجوگر «ذرهبین» با رویکرد تلفیقی (یعنی ترکیب دادههای خزش ذرهبین با نتایج گوگل) توانسته است موفقیت قابل قبولی کسب کند. خصوصاً که نسخه مناسبسازی شده دانشآموزی آن با نام «شادبین» نیز در نرمافزار آموزش مجازی «شاد» گنجانده شده است.
شکل 66: موتور جستجوی شادبین که سعی شده ویژه استفاده دانشآموزان بهینهسازی شود.
در کنار این موارد «جستجوی عمودی»[25]، یعنی استفاده از جستجوگرهای تخصصی و موضوعی، نیز یکی از راهکارهای متداول در دنیا برای یافتن سریعتر اطلاعات خاص است. مثلاً: «Trulia.com» و «Nuroa.com» جستجوگرهای تخصصی ملک و زمین در آمریکا و اروپا هستند، یا «Yelp.com» جستجوگر تخصصی اماکن و کسبوکارهاست که دیدگاه مراجعین به آنها را جمعآوری کرده و به کاربران خود ارائه میکند، یا جستجوگر «Findmypast.com»، «Origins.net» و «Movaco.com» ابزارهای یافتن شجرهنامه و اصالتاند، یا پایگاه «Archive.org» که آرشیو و جستجوگر نسخه پشتیبان و قدیمی تارنماهای گوناگون در زمانهای مختلف است.
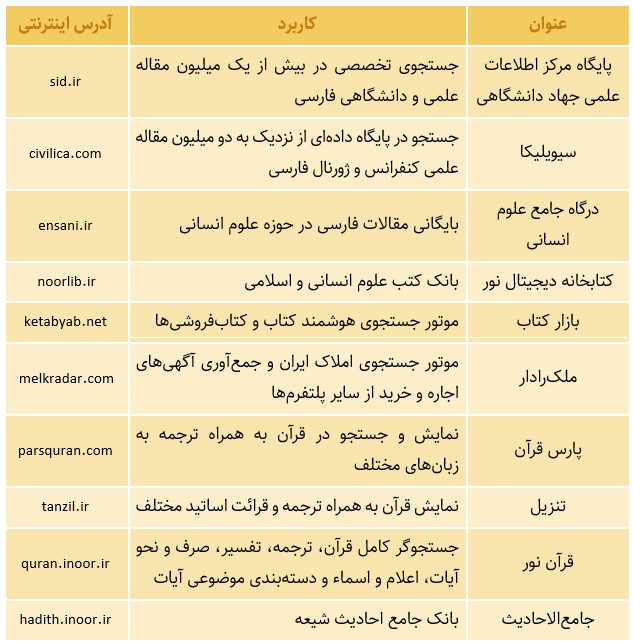
جدول 6: برخی از جستجوگرهای تخصصی و موضوعی فارسی
[1] File Transfer Protocol: سازوکار چگونگی ارسال و دریافت پرونده در یک شبکه رایانهای
[2] https://www.webdesignmuseum.org/web-design-history/archie-the-first-search-engine-1990
[3] Hyper Text Markup Language: (به فارسی زبان نشانهگذاری ابرمتنی یا زنگام) زبان توصیف ساختار صفحات وب است که برای مرورگرها مشخص میکند شکل ظاهری صفحه تارنما را چطور نمایش دهند.
[4] Metadata: به دادههایی گفته میشود که جزئیات یک داده دیگر را تشریح میکند. مثلاً نام نویسنده متن یا زمان انتشار و ویرایش یا نوع دستگاهی که محتوا توسط آن تولید شده یا …
[5] Web Directories
[6] https://www.webdesignmuseum.org/gallery/yahoo-1994
[7] Search Engines
[8] «جُستار» (Query) همان عبارتی است که کاربر در جویشگر وارد و آن را جستجو میکند.
[9] https://www.youtube.com/watch?v=LVV_93mBfSU
[10] https://dev.to/gbengelebs/how-search-engines-work-finding-a-needle-in-a-haystack-4lnp
[11] Search Engine Optimization
[12] https://www.researchgate.net/publication/271899710_Linguistic_Capitalism_and_Algorithmic_Mediation
[13] https://www.oberlo.com/statistics/how-does-google-make-money
[14] پرونده رخداد یا Log پرونده (فایل) است که هر بار که رویدادی خاص در سیستم شما رخ دهد به صورت خودکار تولید میشود. پروندههای لاگ معمولا شامل مهر زمانی هستند و هر آنچه در پس سیستمعاملها یا برنامههای نرمافزاری اتفاق میافتد را ضبط و ثبت میکنند.
[15] اصطلاح «Filter Buble» را اولین بار در سال 1389/2010 آقای «ایلای پاریسر» (Eli Pariser) فعال و کنشگر اینترنتی آمریکایی در نقد الگوریتم شخصیسازی جستجوگر گوگل مطرح کرد و حساسیتها را به این موضوع برانگیخت.
[16] https://gs.statcounter.com/search-engine-market-share
[17] https://www.baidu.com
[18] https://www.yandex.com
[19] https://naver.com
[20] DuckDuckGo.com
[21] https://duckduckgo.com/duckduckgo-help-pages/company/how-duckduckgo-makes-money
[22] https://www.startpage.com
[23] Metasearch engine
[24] https://yacy.net
[25] Vertical search




